Climate Risk Data Platform
Serverless ETL platform ingesting 10+ TB of climate risk data annually on AWS Glue + PySpark — shipped in under 3 months, feeding ML models used in mortgage risk decisions.
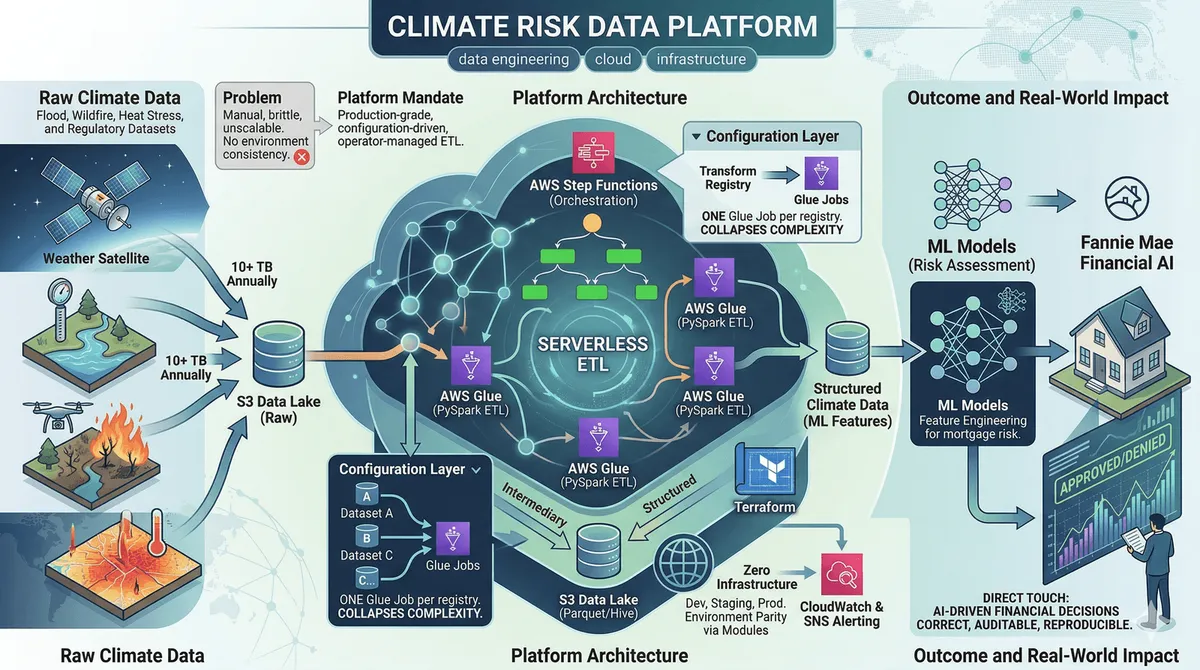
The Problem
Fannie Mae’s climate risk team needed to turn large volumes of third-party climate datasets — property-level flood risk, wildfire exposure, heat stress indices — into structured, queryable data that downstream ML models and regulatory reporting pipelines could consume reliably.
The existing approach was brittle: manual file transfers, ad-hoc scripts, no environment consistency, no way to onboard a new dataset without writing new code. The mandate was to build something production-grade that could process 10+ TB annually, run across multiple environments without modification, and be operated by the data team — not the engineering team.
Architecture
The platform is serverless end-to-end. AWS Glue handles compute (PySpark jobs), Step Functions orchestrates execution and error handling, S3 is the storage layer (Parquet, Hive-partitioned by dataset and date), and everything is provisioned by Terraform.
The key architectural decision was making the transform logic configuration-driven. Rather than one Glue job per dataset, there’s one job that reads a transform registry at runtime. Adding a new vendor dataset means writing a config entry, not a new job — no deployment, no code review, no engineering time.
Components:
- Glue ETL jobs — PySpark handles raw ingestion, schema normalization, type coercion, and partitioned writes. Each job is idempotent and safe to re-run.
- Step Functions state machine — sequences job execution, handles retries with exponential backoff, routes failures to a dead-letter path with structured error context (dataset, partition, error type).
- Transform registry — a config layer that maps dataset schemas, field mappings, and validation rules. Engineering owns the format; the data team owns the entries.
- Terraform modules — reusable modules for Glue jobs, IAM boundaries (least-privilege per job), S3 bucket policies, and CloudWatch alarms. Environment differences are
.tfvarsonly — dev, staging, and prod are structurally identical. - CloudWatch + SNS alerting — job failures and data quality anomalies trigger alerts with enough context to diagnose without re-running the job.
Key Decisions
Glue over EMR: At this data volume, EMR requires manual sizing, cluster management, and hourly billing regardless of utilization. Glue is serverless — capacity scales automatically and billing is per DPU-second. For a burst-heavy workload that isn’t running continuously, the cost difference is material.
Configuration-driven transforms over per-dataset jobs: The platform ingests 15+ distinct datasets from four vendors. A per-dataset codebase means 15 separate jobs to test, deploy, and maintain — and every new dataset is a full engineering engagement. The configuration layer collapses that to one job with a growing registry. This directly enabled the data team to onboard new datasets the following quarter without engineering involvement.
Step Functions over Airflow: The team had no existing Airflow infrastructure and no ops capacity to run it. Step Functions integrates natively with Glue, Lambda, and SNS — zero additional infrastructure, and failure handling is first-class and fully auditable.
Terraform modules over inline config: Infrastructure duplication across environments is where things quietly diverge and break. Modules enforce structural parity — if it works in staging, prod is the same code with different variable values.
Why It Matters
Climate risk data feeds models that affect mortgage pricing, insurance rates, and regulatory capital requirements across millions of properties. The pipeline has to be correct, auditable, and reproducible. That rigor — idempotent jobs, environment parity via IaC, structured failure context — is the same foundation reliable ML feature pipelines and model training infrastructure need at scale. This is backend work that directly touches AI-driven financial decisions.
Outcome
- Production deployment in under 3 months from kickoff
- Infrastructure cost ~30% under initial estimates (serverless pricing model)
- Three new datasets onboarded the following quarter with zero engineering time
- Data team now handles the majority of pipeline issues independently via runbooks
Next project
Fattoruso Ingegneria — Business Website →